7 minutes
RITSEC CTF 2026 - Reversing Writeups (Part 1): T-reasure Chest
Introduction
Participating in RITSEC CTF 2026, a Jeopardy-style CTF of intermediate difficulty, was a great opportunity to sharpen my skills across different areas of cybersecurity. I took part in the competition with the team Echelon Obscura, where I served as the team captain and we ultimately placed 147th out of 663 teams. The event was both challenging and highly enjoyable, offering a well-balanced mix of problems that required both technical depth and creative thinking under time pressure.
For this competition, I focused exclusively on the Reversing category, tackling challenges that required analyzing compiled binaries and uncovering hidden logic. In this series of posts, I’ll document the challenges I solved, walking through both my reasoning process and the technical steps involved. The aim is not just to present solutions, but to highlight practical reversing techniques and the kind of analytical mindset that proves valuable during CTFs.
With that in mind, I’ll start with one of the first reversing challenges I tackled during the competition, titled “T-reasure Chest”. This challenge serves as a good introduction to the category, as it combines straightforward analysis with just enough ambiguity to require careful inspection of the binary.
Challenge Overview
The following description was provided as part of the challenge, along with a binary file named treasure:
“Score! You found a treasure chest! Now if only you could figure out how to unlock it… maybe there’s a magic word?”
The first thing I did was to use the file command to gather basic information about the binary:
$ file treasure
treasure: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /nix/store/8p33is69mjdw3bi1wmi8v2zpsxir8nwd-glibc-2.40-66/lib/ld-linux-x86-64.so.2, for GNU/Linux 3.10.0, stripped
From this, we can immediately see that the binary is a 64-bit ELF executable for x86-64 Linux and is dynamically linked, meaning it depends on external shared libraries at runtime.
Another important detail is that it is stripped, so symbol names are removed. This makes the analysis slightly harder since we lose function names and have to rely more on control flow and disassembly.
The interpreter path also suggests it was built in a Nix-based environment, as indicated by the /nix/store/... glibc loader path. Nix is a declarative package manager and build system that stores dependencies in isolated paths under /nix/store, ensuring reproducible builds. While not directly relevant to exploitation, it gives some context about the build environment.
Static Analysis
At this point, I began the static analysis by opening the binary in Ghidra. After locating the main function and applying some basic renaming and cleanup, the decompiled logic became much easier to follow.
The function looked like this:
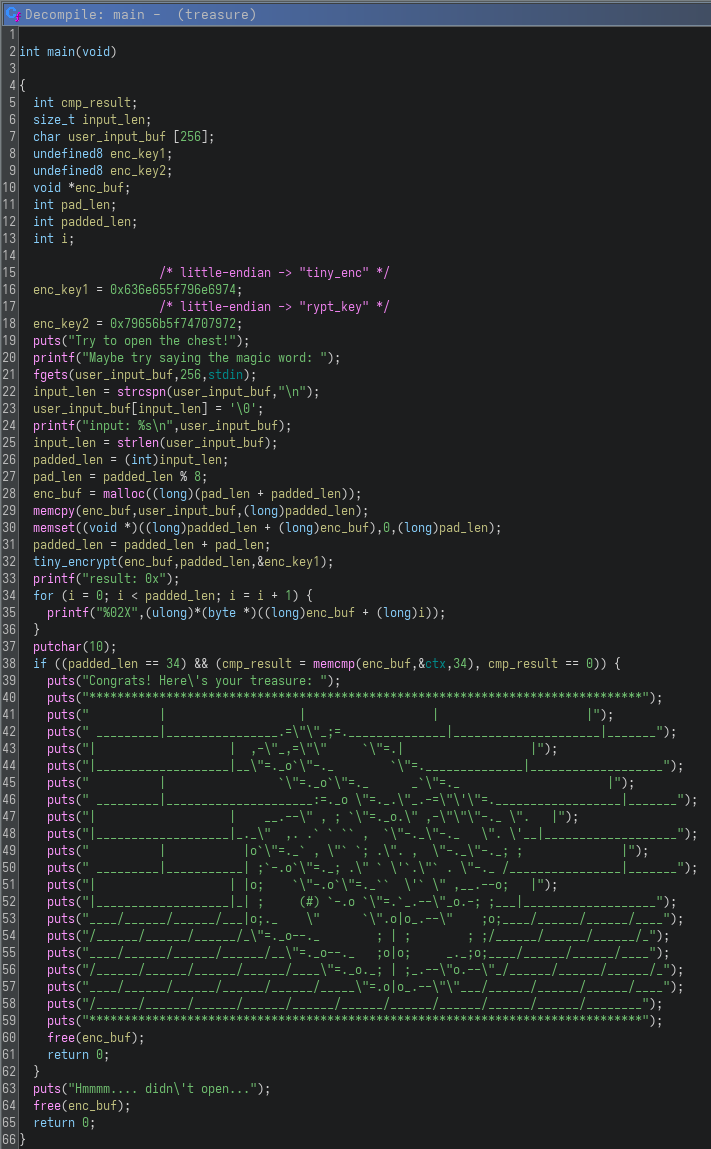
From a high-level perspective, this function implements a classic input validation and transformation routine.
The program first prompts the user for a “magic word” and stores it in a buffer. It then removes the trailing newline and computes the input length. The input is then padded to an 8-byte boundary, with any remaining space filled with zeroes, suggesting block-aligned processing.
After preparation, the buffer is passed into a function I named tiny_encrypt, along with a key constructed from two hardcoded 64-bit values (enc_key1 and enc_key2). These values form the encryption key used in the transformation step.
Once encrypted, the program prints the resulting buffer in hexadecimal form, allowing observation of the transformation output. Finally, it performs a critical check using memcmp against a hardcoded buffer (ctx) and verifies that the total length is exactly 34 bytes. If both conditions are satisfied, the program prints the success message and reveals the “treasure”. Otherwise, it prints a failure message and exits.
At this point, the objective becomes clear: determine the correct input that, after processing through tiny_encrypt, produces the expected 34-byte ciphertext stored in ctx.
Next, I analyzed the encryption routine itself, starting with tiny_encrypt:
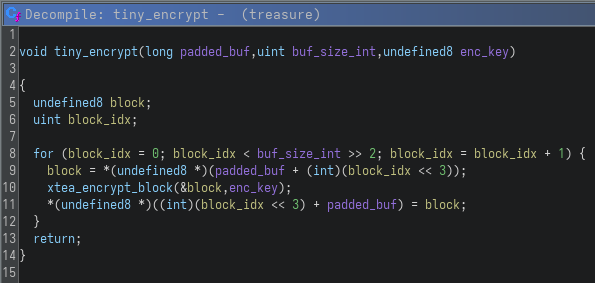
This function is essentially a wrapper over a block cipher operation. It iterates over the input buffer in 8-byte (64-bit) blocks, extracts each block, encrypts it using xtea_encrypt_block and writes it back into memory. The function name xtea_encrypt_block was assigned by me after analyzing the underlying logic and recognizing the structure of the algorithm in the later decompiled function (spoiler alert!). The use of 64-bit blocks immediately suggests a block cipher operating on two 32-bit words per iteration, which is characteristic of TEA-family designs and provides a strong initial hint toward XTEA.
The core logic is implemented in xtea_encrypt_block:
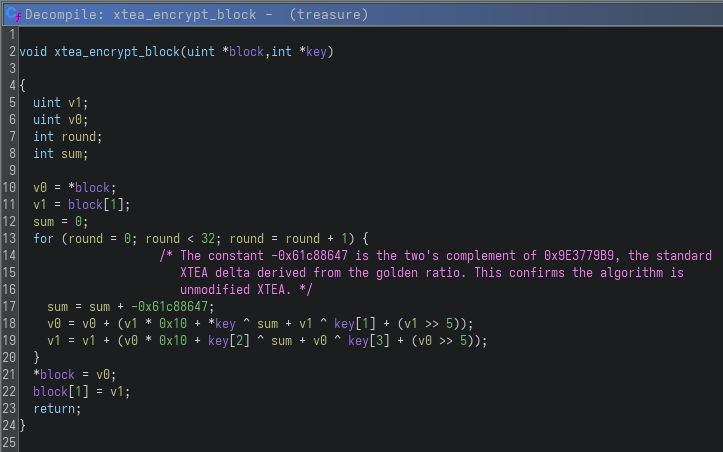
At this point, it becomes clear that the challenge is using XTEA (eXtended Tiny Encryption Algorithm), a lightweight block cipher designed as an improvement over TEA (Tiny Encryption Algorithm). XTEA operates on 64-bit blocks split into two 32-bit halves (v0 and v1) and uses a 128-bit key divided into four 32-bit subkeys.
One of the most important details in this implementation is the constant -0x61c88647. This value is the two’s complement representation of 0x9E3779B9, which is a well-known constant in cryptography. In signed 32-bit arithmetic, -0x61c88647 and 0x9E3779B9 represent the same underlying bit pattern.
The constant 0x9E3779B9 is derived from the golden ratio and is commonly used as the delta value in XTEA. The role of this constant is to ensure good diffusion by preventing patterns in the round key schedule. In XTEA, this value is repeatedly added to a running sum in each round, which drives the key mixing process.
Seeing this exact constant confirms that the implementation is standard, unmodified XTEA, rather than a custom or weakened variant. This is an important observation, because it means the encryption behavior is well-defined and can be reliably reversed using known cryptographic properties of XTEA.
XTEA itself is a symmetric block cipher, meaning the same key is used for both encryption and decryption. It was designed to be simple and efficient, making it suitable for environments with limited resources. Historically, it has been used in embedded systems, firmware and lightweight encryption scenarios, although it is not considered secure by modern cryptographic standards due to weaknesses discovered over time.
In the context of this challenge, however, its importance lies in the fact that it is fully reversible, which becomes the key to recovering the original “magic word” once the correct ciphertext target is identified.
Getting the flag
With this understanding in place, the final step was to reverse the encryption process and recover the original input that produces the expected ciphertext.
Since the encryption used is XTEA and the implementation follows the standard 32-round structure with a fixed delta (0x9E3779B9), decryption can be performed by reversing the round operations. The only required inputs were the extracted ciphertext (ctx) from Ghidra and the static key reconstructed from the binary.
The following Python script implements the decryption logic:
#!/usr/bin/env python3
import struct
ctx = bytes([
0x38,0x75,0x5b,0xcb, 0x44,0xd2,0xbe,0x5d,
0x96,0x9c,0x56,0x43, 0xea,0x98,0x06,0x75,
0x4a,0x48,0x13,0xe6, 0xd4,0xe8,0x8e,0x4f,
0x72,0x70,0x8b,0xff, 0xdc,0x99,0xf8,0x76,
0xc5,0xc9,
])
key = struct.unpack('<4I', b'tiny_encrypt_key')
# (0x796e6974, 0x636e655f, 0x74707972, 0x79656b5f)
def u32(x): return x & 0xFFFFFFFF
def xtea_decrypt(v0, v1):
delta = 0x9E3779B9
s = u32(delta * 32)
for _ in range(32):
v1 = u32(v1 - ((u32(v0*16)+key[2]) ^ u32(s+v0) ^ (u32(v0>>5)+key[3])))
v0 = u32(v0 - ((u32(v1*16)+key[0]) ^ u32(s+v1) ^ (u32(v1>>5)+key[1])))
s = u32(s - delta)
return v0, v1
out = bytearray()
for i in range(len(ctx) // 8):
v0, v1 = struct.unpack_from('<2I', ctx, i*8)
d0, d1 = xtea_decrypt(v0, v1)
out += struct.pack('<2I', d0, d1)
print(out[:33].rstrip(b'\x00').decode())
Running the script processes the ciphertext block by block, applies the inverse XTEA rounds, and reconstructs the original plaintext. After stripping padding bytes, the recovered string is printed, which corresponds directly to the flag for the challenge:
$ python solve.py
RS{oh_its_a_TEAreasure_chest}
This completes the reversing process: starting from a stripped binary, identifying the use of XTEA encryption and finally leveraging its reversibility to recover the flag from the encrypted data.
Conclusion
This challenge was a solid introduction to reversing in the context of CTF cryptography-based binaries. Even though the initial entry point looked like a simple “magic word” check, the underlying logic quickly escalated into a full block cipher implementation.
One of the key takeaways from this challenge was how important it is to recognize common cryptographic patterns early during static analysis. The structure of the code, especially the 64-bit block handling and the round-based mixing function, strongly hinted toward a known algorithm family. Identifying XTEA significantly reduced the complexity of the problem, since it is a well-documented and fully reversible cipher.
Another useful aspect was working with stripped binaries. Without function names or symbols, most of the analysis relied on understanding behavior rather than relying on metadata. Renaming functions like tiny_encrypt during analysis also helped make the decompiled code much easier to reason about.
Overall, the challenge reinforced a common CTF reversing workflow: start from high-level behavior, identify known primitives and reduce the problem until it becomes a direct implementation task.